Character sets and collations in MySQL
Understanding the differences between character sets and collations in MySQL.
Character sets and collations are fundamentally important concepts to understand when dealing with string columns in MySQL. A slight misunderstanding of either can lead to poor performance or unexpected errors when inserting data.
A character set defines the characters allowed to go in a column. A collation is a set of rules for comparing those characters. Each character set can have multiple collations, but a collation may only belong to one character set.
Character sets in MySQL
MySQL supports a wide range of character sets, which you can view by selecting from the information_schema database.
SELECT * FROM information_schema.character_sets ORDER BY character_set_name
This will list out all of the character sets, along with their default collations. Every character set has one default collation.
| CHARACTER_SET_NAME | DEFAULT_COLLATE_NAME | DESCRIPTION | MAXLEN |
|--------------------|----------------------|---------------------------------|--------|
| armscii8 | armscii8_general_ci | ARMSCII-8 Armenian | 1 |
| ascii | ascii_general_ci | US ASCII | 1 |
| big5 | big5_chinese_ci | Big5 Traditional Chinese | 2 |
| binary | binary | Binary pseudo charset | 1 |
| cp1250 | cp1250_general_ci | Windows Central European | 1 |
| cp1251 | cp1251_general_ci | Windows Cyrillic | 1 |
| cp1256 | cp1256_general_ci | Windows Arabic | 1 |
| cp1257 | cp1257_general_ci | Windows Baltic | 1 |
| cp850 | cp850_general_ci | DOS West European | 1 |
| cp852 | cp852_general_ci | DOS Central European | 1 |
| cp866 | cp866_general_ci | DOS Russian | 1 |
| cp932 | cp932_japanese_ci | SJIS for Windows Japanese | 2 |
| dec8 | dec8_swedish_ci | DEC West European | 1 |
| eucjpms | eucjpms_japanese_ci | UJIS for Windows Japanese | 3 |
| euckr | euckr_korean_ci | EUC-KR Korean | 2 |
| gb18030 | gb18030_chinese_ci | China National Standard GB18030 | 4 |
| gb2312 | gb2312_chinese_ci | GB2312 Simplified Chinese | 2 |
| gbk | gbk_chinese_ci | GBK Simplified Chinese | 2 |
| geostd8 | geostd8_general_ci | GEOSTD8 Georgian | 1 |
| greek | greek_general_ci | ISO 8859-7 Greek | 1 |
| hebrew | hebrew_general_ci | ISO 8859-8 Hebrew | 1 |
| hp8 | hp8_english_ci | HP West European | 1 |
| keybcs2 | keybcs2_general_ci | DOS Kamenicky Czech-Slovak | 1 |
| koi8r | koi8r_general_ci | KOI8-R Relcom Russian | 1 |
| koi8u | koi8u_general_ci | KOI8-U Ukrainian | 1 |
| latin1 | latin1_swedish_ci | cp1252 West European | 1 |
| latin2 | latin2_general_ci | ISO 8859-2 Central European | 1 |
| latin5 | latin5_turkish_ci | ISO 8859-9 Turkish | 1 |
| latin7 | latin7_general_ci | ISO 8859-13 Baltic | 1 |
| macce | macce_general_ci | Mac Central European | 1 |
| macroman | macroman_general_ci | Mac West European | 1 |
| sjis | sjis_japanese_ci | Shift-JIS Japanese | 2 |
| swe7 | swe7_swedish_ci | 7bit Swedish | 1 |
| tis620 | tis620_thai_ci | TIS620 Thai | 1 |
| ucs2 | ucs2_general_ci | UCS-2 Unicode | 2 |
| ujis | ujis_japanese_ci | EUC-JP Japanese | 3 |
| utf16 | utf16_general_ci | UTF-16 Unicode | 4 |
| utf16le | utf16le_general_ci | UTF-16LE Unicode | 4 |
| utf32 | utf32_general_ci | UTF-32 Unicode | 4 |
| utf8 | utf8_general_ci | UTF-8 Unicode | 3 |
| utf8mb4 | utf8mb4_0900_ai_ci | UTF-8 Unicode | 4 |
At the bottom of this table, you'll notice two character sets described as UTF-8 Unicode. The utf8 charset has a MAXLEN of 3 while the utf8mb4 has a MAXLEN of 4. What's being described here is the maximum allowed length, in bytes, per character.
According to the UTF-8 spec, each character is allowed four bytes, meaning MySQL's utf8 charset was never actually UTF-8 since it only supported three bytes per character. In MySQL 8, utf8mb4 is the default character set and the one you will use most often. utf8 is left for backwards compatibility and should no longer be used.
How do you define a character set?
There are a few ways to define the character set of a column. If you don't specify a character set at the table or column level, the server default of utf8mb4 will be applied (unless you've explicitly declared a different server or database default).
We can prove this by creating a table with no character set information and then reading it back:
CREATE TABLE no_charset (
my_column VARCHAR(255)
);
SHOW CREATE TABLE no_charset;
The resulting CREATE TABLE statement shows that the default charset and collation have been applied.
CREATE TABLE `no_charset` (
`my_column` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
Defining at the table level
Instead of allowing the database or server default to apply, you can explicitly set the character set at the table level by using the CHARSET=[charset] notation. Here, we'll create a table where all character columns have the latin1 charset:
CREATE TABLE `no_charset` (
`my_column` VARCHAR(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
Defining at the column level
Finally, you can set the character set at the column level. This is the most specific and overrides any table-level settings.
CREATE TABLE `mixed_collations` (
`explicitly_set` VARCHAR(255) CHARACTER SET latin1,
`implicitly_set` VARCHAR(255)
);
Reading this table back with the SHOW CREATE TABLE statement makes it clear that the table is utf8mb4, but the explicitly_set column is latin1:
CREATE TABLE `mixed_collations` (
`explicitly_set` VARCHAR(255) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL,
`implicitly_set` VARCHAR(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
This is the most specific way to declare a character set.
A column-level specification will override a table-level specification, a table-level specification overrides the database default, and a database-level charset overrides the server default.
Collations in MySQL
While character sets define the legal characters that can be stored in a column, collations are rules that determine how string comparisons are made. If you are sorting or comparing strings, MySQL uses the collation to decide the order and whether the strings are the same.
You can show all the collations by querying the information_schema table again. There are a lot of collations, so we'll restrict the results to only collations that apply to the utf8mb4 charset.
SELECT
*
FROM
information_schema.collations
WHERE
character_set_name = 'utf8mb4'
ORDER BY
collation_name
This query will display all the collations, related character set names, whether they are default, and a few other pieces of information. Notice that for each character set, there is one default collation. For example, utf8mb4_0900_ai_ci is the default collation for the utf8mb4 character set.
| COLLATION_NAME | CHARACTER_SET_NAME | ID | IS_DEFAULT | IS_COMPILED | SORTLEN | PAD_ATTRIBUTE |
|----------------------------|--------------------|-----|------------|-------------|---------|---------------|
| utf8mb4_0900_ai_ci | utf8mb4 | 255 | Yes | Yes | 0 | NO PAD |
| utf8mb4_0900_as_ci | utf8mb4 | 305 | | Yes | 0 | NO PAD |
| utf8mb4_0900_as_cs | utf8mb4 | 278 | | Yes | 0 | NO PAD |
| utf8mb4_0900_bin | utf8mb4 | 309 | | Yes | 1 | NO PAD |
| utf8mb4_bin | utf8mb4 | 46 | | Yes | 1 | PAD SPACE |
| utf8mb4_croatian_ci | utf8mb4 | 245 | | Yes | 8 | PAD SPACE |
| utf8mb4_cs_0900_ai_ci | utf8mb4 | 266 | | Yes | 0 | NO PAD |
| utf8mb4_cs_0900_as_cs | utf8mb4 | 289 | | Yes | 0 | NO PAD |
| utf8mb4_czech_ci | utf8mb4 | 234 | | Yes | 8 | PAD SPACE |
| utf8mb4_danish_ci | utf8mb4 | 235 | | Yes | 8 | PAD SPACE |
| utf8mb4_da_0900_ai_ci | utf8mb4 | 267 | | Yes | 0 | NO PAD |
| utf8mb4_da_0900_as_cs | utf8mb4 | 290 | | Yes | 0 | NO PAD |
| utf8mb4_de_pb_0900_ai_ci | utf8mb4 | 256 | | Yes | 0 | NO PAD |
| utf8mb4_de_pb_0900_as_cs | utf8mb4 | 279 | | Yes | 0 | NO PAD |
| [omitted for brevity] | ... | ... | | ... | ... | ... |
| utf8mb4_vietnamese_ci | utf8mb4 | 247 | | Yes | 8 | PAD SPACE |
| utf8mb4_vi_0900_ai_ci | utf8mb4 | 277 | | Yes | 0 | NO PAD |
| utf8mb4_vi_0900_as_cs | utf8mb4 | 300 | | Yes | 0 | NO PAD |
| utf8mb4_zh_0900_as_cs | utf8mb4 | 308 | | Yes | 0 | NO PAD |
Collations follow a naming scheme whereby the character set forms a prefix, and the suffix combines attributes of the collation.
Here is a breakdown of a few of the suffixes you might see:
| Suffix | Meaning |
|--------|--------------------|
| _ai | Accent-insensitive |
| _as | Accent-sensitive |
| _ci | Case-insensitive |
| _cs | Case-sensitive |
| _ks | Kana-sensitive |
| _bin | Binary |
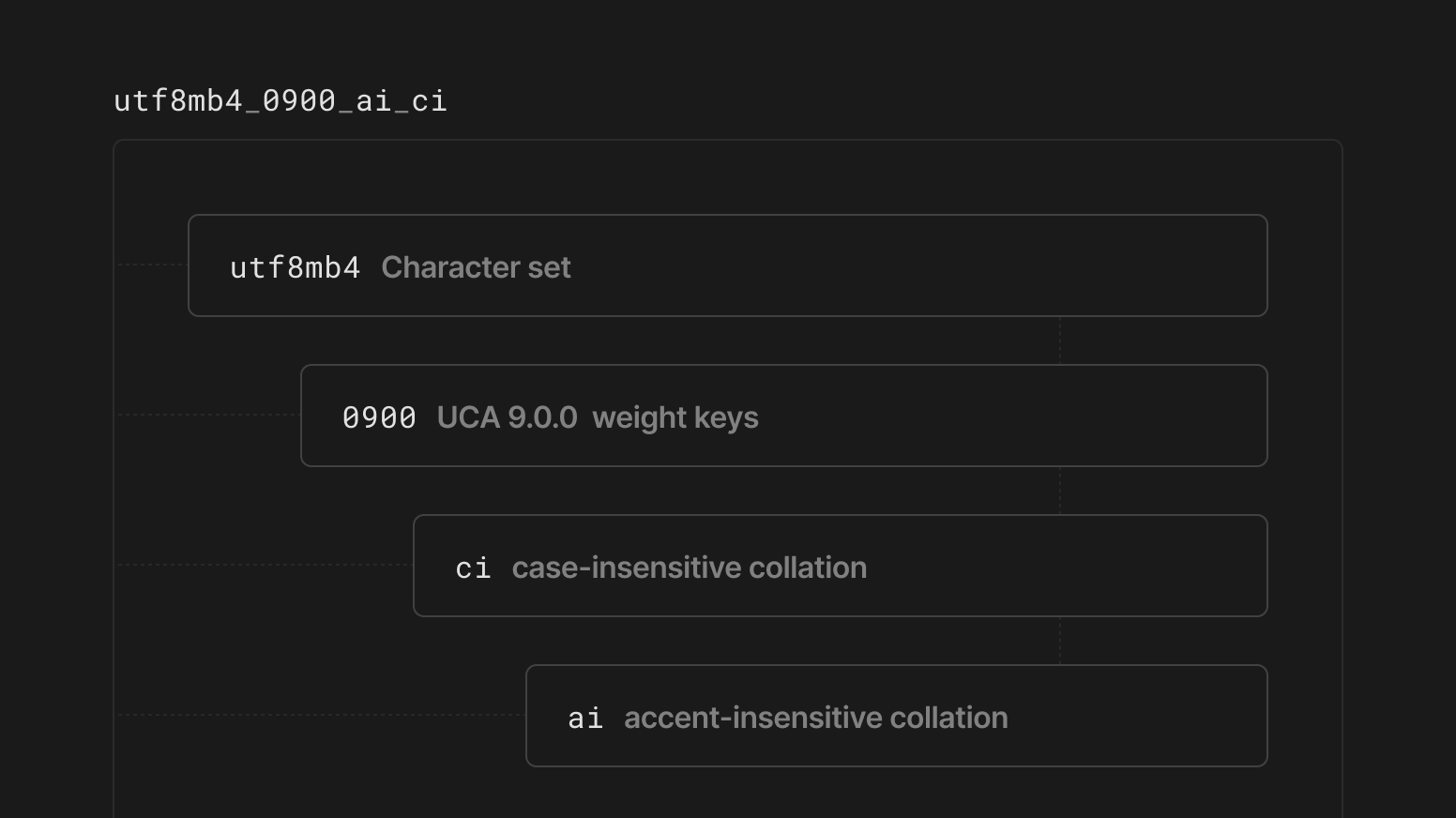
Let's take the default utf8mb4 collation of utf8mb4_0900_ai_ci and expand it slightly.
The utf8mb4 part declares it belongs to the utf8mb4 charset. The 0900 references the UCA 9.0.0 weight keys. _ai means the collation is accent-insensitive, while _ci declares it case-insensitive.
This allows us to confidently answer the question, "are string comparisons case-sensitive?" The answer, of course, is: it depends! It depends on the collation.
Let's prove this by explicitly casting strings using the COLLATE keyword.
SELECT "MySQL" COLLATE utf8mb4_0900_ai_ci = "mysql" COLLATE utf8mb4_0900_ai_ci;
Running this statement gives us a value of 1, meaning MySQL treats the two strings as equal. If we were to rerun it with a case-sensitive collation, we'd expect (and obtain!) a different result:
SELECT "MySQL" COLLATE utf8mb4_0900_as_cs = "mysql" COLLATE utf8mb4_0900_as_cs;
This query returns a value of 0, meaning MySQL sees these strings as unique because they are cased differently.
The same logic holds for accent sensitivity. With an accent-insensitive collation, résumé and resume would be deemed identical because the accents would be ignored.
How do you define a collation?
Like character sets, collations can be set at both the table and column levels. If a collation is not explicitly defined, MySQL uses the default collation of the character set.
To define a collation at the table level, you can use the COLLATE clause in the CREATE TABLE statement. For example, you can create a table where all character columns use the utf8mb4_bin collation:
CREATE TABLE table_with_collation (
my_column VARCHAR(255)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
If you want to define the collation at the column level, you can do so in the column definition. The following example creates a table with two columns: explicitly_set uses the utf8mb4_general_ci collation, and implicitly_set uses the default collation from the utf8mb4 charset, which is utf8mb4_0900_ai_ci.
CREATE TABLE table_with_collation (
`explicitly_set` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci,
`implicitly_set` varchar(255)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
You can also change the collation of a column in an existing table using the ALTER TABLE statement:
ALTER TABLE table_with_collation
CHANGE `explicitly_set` `explicitly_set` varchar(255)
CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
Summary
Understanding character sets and collations is fundamental when dealing with string data in MySQL. A character set defines the legal characters that can be stored in a column, while a collation determines how string comparisons are made.
- A character set can be defined at the column level, the table level, or it can be inherited from the database or server default. The most specific level (column > table > database > server) is used.
- A collation can be defined at the column level, the table level, or it can be inherited from the character set default. Again, the most specific level is used.
- The character set and collation of a column affect how data is stored and how it is compared and sorted. Be mindful of these settings to ensure the correct behavior and optimal performance when designing your database.
If you are unsure which character set or collation to use, the MySQL default utf8mb4 character set and its default utf8mb4_0900_ai_ci collation are usually good choices. They support all Unicode characters and provide case-insensitive and accent-insensitive comparisons.